Daten, Information, Evidenz

Möglicherweise werden die Inhalte automatisch übersetzt.
Am 27. Januar 2023 überrascht der Startbildschirm von Windows 11 mit einer im Deutschen trivialen Aussage:
Breitmaulnashörner sind nicht weiss, sondern eher gräulich. Vielleicht wurden sie nach Ihrem Maul benannt.
Die Ursache dieser in der deutschen Sprache trivialen Aussage erschliesst sich aus dem Kontext des mutmasslichen Englischen Originaltextes:
(WWF, 2023)Im Englischen heißen Breitmaulnashörner White Rhinos, also „Weiße Nashörner“, obwohl sie nicht weiß sind. Es wird angenommen, dass die Bezeichnung „White Rhinos“ auf ein Missverständnis zurückzuführen ist. Das Afrikaans-Wort „wyd“ bedeutet übersetzt „breit“, klingt aber dem englischen „white“ sehr ähnlich. Vermutlich wurden die Breitmaulnashörner von englischen Siedlern so White Rhinos genannt.
Wo ist der Bezug zu Pflege/Aging in Place?
Die Qualität des Kontextes bzw. der Bildbeschreibungen kann im Kontext der Barrierefreiheit relevant werden. Und schlägt im Kontext der Künstlichen Intelligenzz etwa nieder in automatisch generierten Bildsbeschreibungen (weiterführend: The Verge 2022)

Martina Mara erläutert Verzerrungen in der KI am Beispiel von Geschlechtszuschreibungen.
Eingangsrätsel: Wie ist das möglich?
- Ein Vater und sein Sohn sind gemeinsam im Auto unterwegs und haben einen furchtbaren Autounfall. Der Vater verstirbt leider an Ort und Stelle.
- Der Sohn wird mit Blaulicht ins Krankenhaus gefahren und sofort in den Operationssaal gebracht
- Der Artzt sieht ihn kurz an und meint, hier müsse man eine Koryphäe zu Rate ziehen.
- Die Koryphäe kommt, sieht den jungen man auf dem Operationstisch und sagt: " Ich kann ihn nicht operieren, er ist mein Sohn"
Bei der Koryphäe handelt es sich um die Mutter des jungen Mannes. Argumentation: Der Begriff der Koryphäe ist meist mit einer männlichen Vorstellung hinterlegt. Deshalb entsteht meist ein Widerspruch zwischen der Vorstellung "Der Vater ist verstorben" und (mutmasslich) "Der Vater ist die Koryphäe"
Bias - Abweichen vom Prototypen
- Abweichungen vom traditionellen Schema benötigen Abweichungen (Bananen - Grüne Bananen)
- Prototypen halten sich hartnäckig, auch wenn sich werte verändern.
Vier Herausforderungen (18:00)
- Challenge 1: Stereotype Rollenbilder in Datensätzen (18:10)
- Kurzgeschichte von ChatGPT - männlich vs weiblich
- Automatisierte Übersetzung - Problem unbestimmter Personalpronomen und fehlenden Kontextes
- Challenge 2: Mangelnde Repräsentanz in Datensätzen (32:05)
- Spracherkennugnssysteme & Dialekt, Lokal- und Generationscolorit
- Mozilla Common Voice & Transparenz der Datensatz-Zusammensetzung
- Mangelhaftes oder falsches Daten-Labeling - Hochzeit in verschiedenen Kulturen
- Mangel an Partizipation in der Produktentwicklung - Mobile aus Baby-Sicht
- Challenge 3: Ungleichverteilung von Wissen und Möglichkeiten zur Mitgestaltung (43:20)
- Wer kennt den Algorithmus?
- Alters- und Geschlechtsunterschiede im Bereich KI/MINT
- Challenge 4: Stereotype Gestaltung von Technologie (50:52)
- Sprachassistenten sind in der Grundeinstellung weiblich.
- Kontra-stereotpe Technologie-Gestaltung: Rehabilitations-Roboter
Forderungen im Fazit (59:53): Wir brauchen:
- Bewusstsein über die Herausforderungen
- bei gleichzeitiger Anerkennung, dass sie sich nicht rein technisch lösen lassen.
- Mehr Diversität
- in den Daten, aus denen wir KI-Systeme lernen lassen
- in der demografischen Zusammensetzung von Entwicklungs-Teams
- in Perspektiven, Expertisen und Mindsets
- in der Ansprache von Zielgruppen für digitale Bildungsangebote
Daten
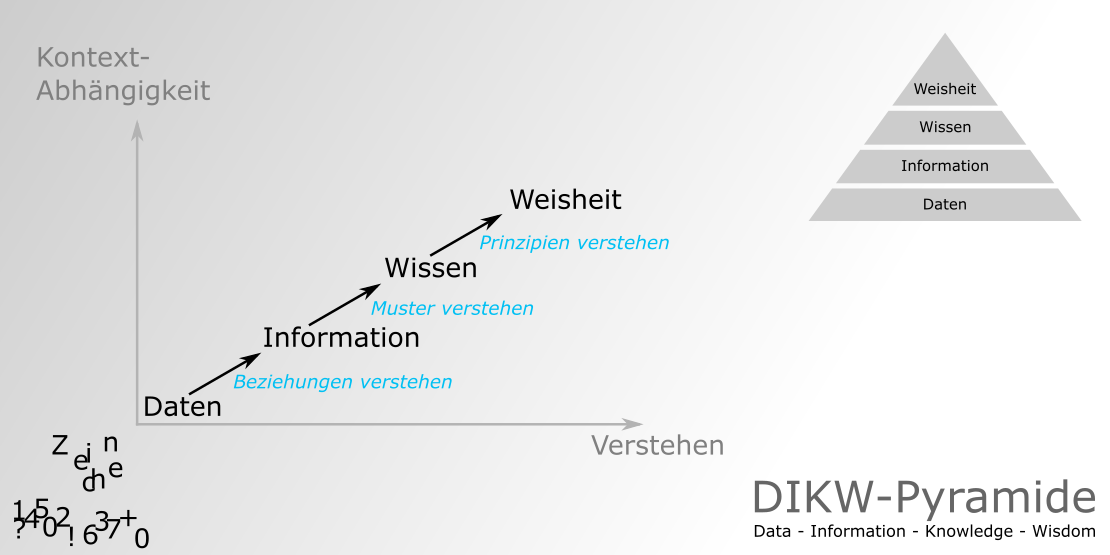
Daten sind die Grundlage für Informationen < Wissen < Weisheit
DIKW steht für die Begriffe Data, Information, Knowledge und Wisdom.
Daten... Daten sind roh. Es existiert einfach und hat keine Bedeutung, die über seine Existenz (an und für sich) hinausgeht. Es kann in jeder Form existieren, nutzbar oder nicht. Es hat keine eigene Bedeutung. Im Computerjargon beginnt eine Tabellenkalkulation im Allgemeinen mit der Speicherung von Daten.
Informationen... Informationen sind Daten, denen durch relationale Verbindungen eine Bedeutung verliehen wurde. Diese „Bedeutung“ kann nützlich sein, muss es aber nicht. Im Computerjargon stellt eine relationale Datenbank Informationen aus den darin gespeicherten Daten her.
Wissen... Wissen ist die angemessene Sammlung von Informationen, deren Zweck es ist, nützlich zu sein. Wissen ist ein deterministischer Prozess. Wenn sich jemand Informationen „auswendig lernt“ (wie es weniger ambitionierte, prüfungsorientierte Schüler oft tun), dann hat er Wissen angesammelt. Dieses Wissen hat für sie eine nützliche Bedeutung, aber es sorgt an und für sich nicht für eine Integration, die zu weiterem Wissen führen würde. Beispielsweise merken sich Grundschulkinder den „Stundenplan“ oder sammeln Wissen darüber an. Sie können Ihnen sagen, dass „2 x 2 = 4“, weil sie dieses Wissen gesammelt haben (es ist in der Stundentabelle enthalten). Auf die Frage, was „1267 x 300“ sei, können sie jedoch nicht richtig antworten, da dieser Eintrag nicht in ihrer Zeittabelle enthalten ist. Um eine solche Frage richtig zu beantworten, sind echte kognitive und analytische Fähigkeiten erforderlich, die erst auf der nächsten Ebene enthalten sind: dem Verständnis. Im Computerjargon nutzen die meisten von uns verwendeten Anwendungen (Modellierung, Simulation usw.) irgendeine Art von gespeichertem Wissen.
Verstehen... Verstehen ist ein interpolativer und probabilistischer Prozess. Es ist kognitiv und analytisch. Es ist der Prozess, durch den ich Wissen übernehmen und aus dem zuvor vorhandenen Wissen neues Wissen synthetisieren kann. Der Unterschied zwischen Verstehen und Wissen ist der Unterschied zwischen „Lernen“ und „Auswendiglernen“. Menschen mit Verständnis können nützliche Maßnahmen ergreifen, weil sie aus dem, was bereits bekannt (und verstanden) ist, neues Wissen oder in manchen Fällen zumindest neue Informationen synthetisieren können. Das heißt, das Verstehen kann auf aktuell vorhandenen Informationen, Wissen und dem Verstehen selbst aufbauen. Im Computerjargon verfügen KI-Systeme über Verständnis in dem Sinne, dass sie in der Lage sind, neues Wissen aus zuvor gespeicherten Informationen und Wissen zu synthetisieren.
Weisheit... Weisheit ist ein extrapolativer und nicht deterministischer, nicht probabilistischer Prozess. Es greift auf alle vorherigen Bewusstseinsebenen zurück und insbesondere auf spezielle Arten menschlicher Programmierung (moralische, ethische Kodizes usw.). Es lädt dazu ein, uns Verständnis zu vermitteln, für das es bisher kein Verständnis gab, und geht dabei weit über das Verständnis selbst hinaus. Es ist die Essenz philosophischen Nachdenkens. Im Gegensatz zu den vorherigen vier Ebenen werden Fragen gestellt, auf die es keine (leicht erreichbare) Antwort gibt und in einigen Fällen auch keinen allgemeingültigen Antwortzeitraum. Weisheit ist daher der Prozess, durch den wir auch zwischen richtig und falsch, gut und schlecht unterscheiden oder urteilen. Ich persönlich glaube, dass Computer nicht über die Fähigkeit verfügen, Weisheit zu besitzen, und dass dies auch nie der Fall sein wird. Weisheit ist ein einzigartiger menschlicher Zustand, oder wie ich es sehe, erfordert Weisheit, dass man eine Seele hat, denn sie wohnt sowohl im Herzen als auch im Verstand. Und eine Seele ist etwas, das Maschinen niemals besitzen werden (oder vielleicht sollte ich das umformulieren, um zu sagen, dass eine Seele etwas ist, das im Allgemeinen niemals eine Maschine besitzen wird).
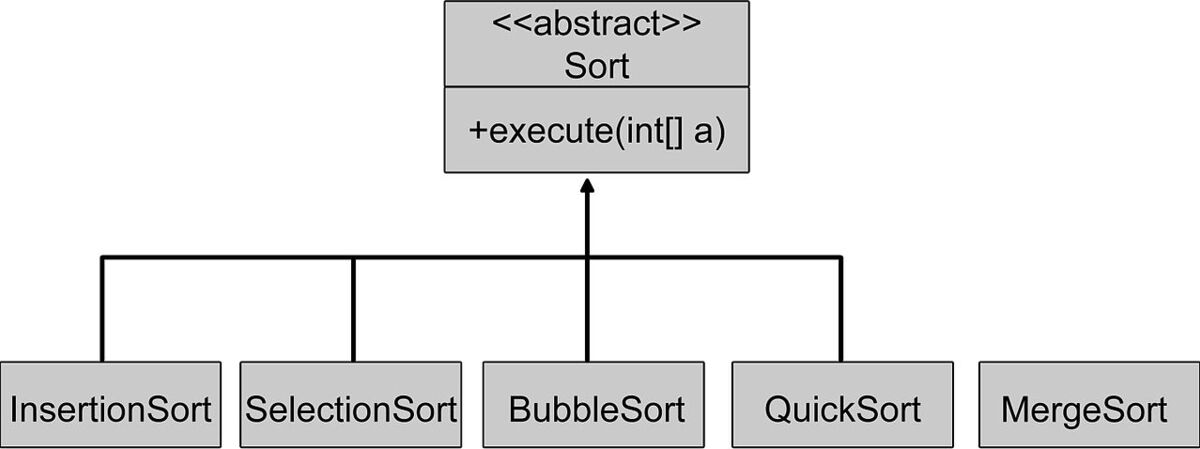
Sortierverfahren unterscheiden sich z.B. in Stabilität, Laufzeit und Datenlimitationen.
- 1:50 Interne vs Externe verfahren
- Intern: Alle zu Sortierenden Daten passen in den Arbeitsspeicher und können auf einen Schlag sortiert werden. Die Datenmenge ist Limitiert.
- 2:19 Extern: Die Datenmenge ist zu gross für den Arbeitsspeicher und muss sequientiell sortiert werden. Die Datenmenge ist Unlimitiert
- 3:00 Stabile vs Instabile Sortierverfahren
- Stabil: die Reihenfolge der Sortierung bleibt erhalten.
- 3:34 Instabil: Die gleiche Reihenfolge ist nicht garantiert (relevant bei teilidentischen Daten)
- 4:23: Space-TimeTradeoff (Benötigter Speicherplatz vs Laufzeit)
- 1:36 - Bubble Sort - https://de.wikipedia.org/wiki/Bubblesort
- 2:33 - Insertion Sort - https://de.wikipedia.org/wiki/Insertionsort
- 3:29 - Selection Sort - https://de.wikipedia.org/wiki/Selectionsort
- 4:11 - Merge Sort - https://de.wikipedia.org/wiki/Mergesort
- 5:21 - Quick Sort - https://de.wikipedia.org/wiki/Quicksort
- 6:54 - Radix Sort - https://de.wikipedia.org/wiki/Radixsort
- 7:55 - Stupid Sort - https://de.wikipedia.org/wiki/Bogosort
Statistik

Im Simpson-Paradoxon scheint es, dass die Bewertung verschiedener Gruppen unterschiedlich ausfällt, je nachdem ob man die Ergebnisse der Gruppen kombiniert oder nicht.
Überwachung & Ethik

Wir können die Stellungahme zur technischen Lösung im Sinne der Akteur-Netzwerk-Theorie auch so lesen, als würde sie unser persönliches Handeln betreffen. So können wir unsere Kontext-Differenzierung für die Stellungnahme erhöhen.
Zur Stellungnahme (PDF) Pressemitteilung
Zentrale Argumente
- Nutzen: Überwachung
- kann ein Beitrag zur Sicherheit, Unterstützung und Effizienzsteigerung sein.
- greift in die Persönlichkeitsrechte/Privatsphäre ein
- Normative Stellungnahme: Überwachung
- darf nicht routinemässig bei Allen Patienten/Bewohnern zum Einsatz kommen
- darf nur in vordefinierten und begründeten Einzelfällen zum Einsatz kommen.
- Erwünschte Effekte
- Frühzeitiges Erkennen von Ereignissen
- Schnelle Kommunikation
- Personelle Entlastung
- Unerwünschte Effekte
- Verlust persönlicher Zuwendung durch funktionalisierung
- Fragmentierte Datenerhebung
- Trennung von Sensorik (Wahrnehmen), Verarbeitung (Erkennen) und Aktorik (Intervention) kann zu unerwünschten Effekten führen
- Alarmmüdigkeit
- Wirksamkeitsnachweise fehlen
Wertebezogene Dimension
- Schutz / Fürsorge / Effizienzüberlegungen ⇔ Selbstbestimmung und Autonomie
- Schutz der Privatsphäre ⇔ Institutionelle Abläufe
- Wahrung der Würde ⇔ Institutionelle Abläufe
- Fürsorge ⇔ Allokation (Personelle mittel / personenzentrierte Versorgung)
- Evidenzbasierung und Einzelfallverstehen: Gutes Tun ⇔ Nicht Schaden
- Dimensionen der Autonomie
- Einschränkung der Bewegungsfreiheit
- Schutz der Professionellen Integritä
Fachliche Dimension
- Fragmentierte Datenerhebung: Werden Notfall-Situationen von der Überwachenden Instanz vollumfänglich erkannt?
- Verzögerungen: Kann nach dem Erkennen einer Situation rasch gehandelt werden?
- Datensparsamkeit: Werden Informationen über das Mass des Notwendigen hinaus erhoben?
- Juristisch: Übt die Überwachung zwang aus - sind die davon betroffenen Menschen Urteilsfähig?
- Zeitliche Dauer: Ist die Überwachung in der Langzeitpflege / im Zu Hause anders zu beurteilen als in der temporären Versorgung?
Rechtliche Dimension
- Persönlichkeitsrechte
- Grundrechte
- Datenschutzgesetze
- öffentliches Recht
- Privatrecht
- Einwilliguntsfähigkeit
- Arbeitsrecht